
Clarwise
Data Lakes: Building Scalable Data Infrastructure
Learn how to design and implement data lakes for modern data architecture. Discover best practices for data ingestion, storage, and processing.
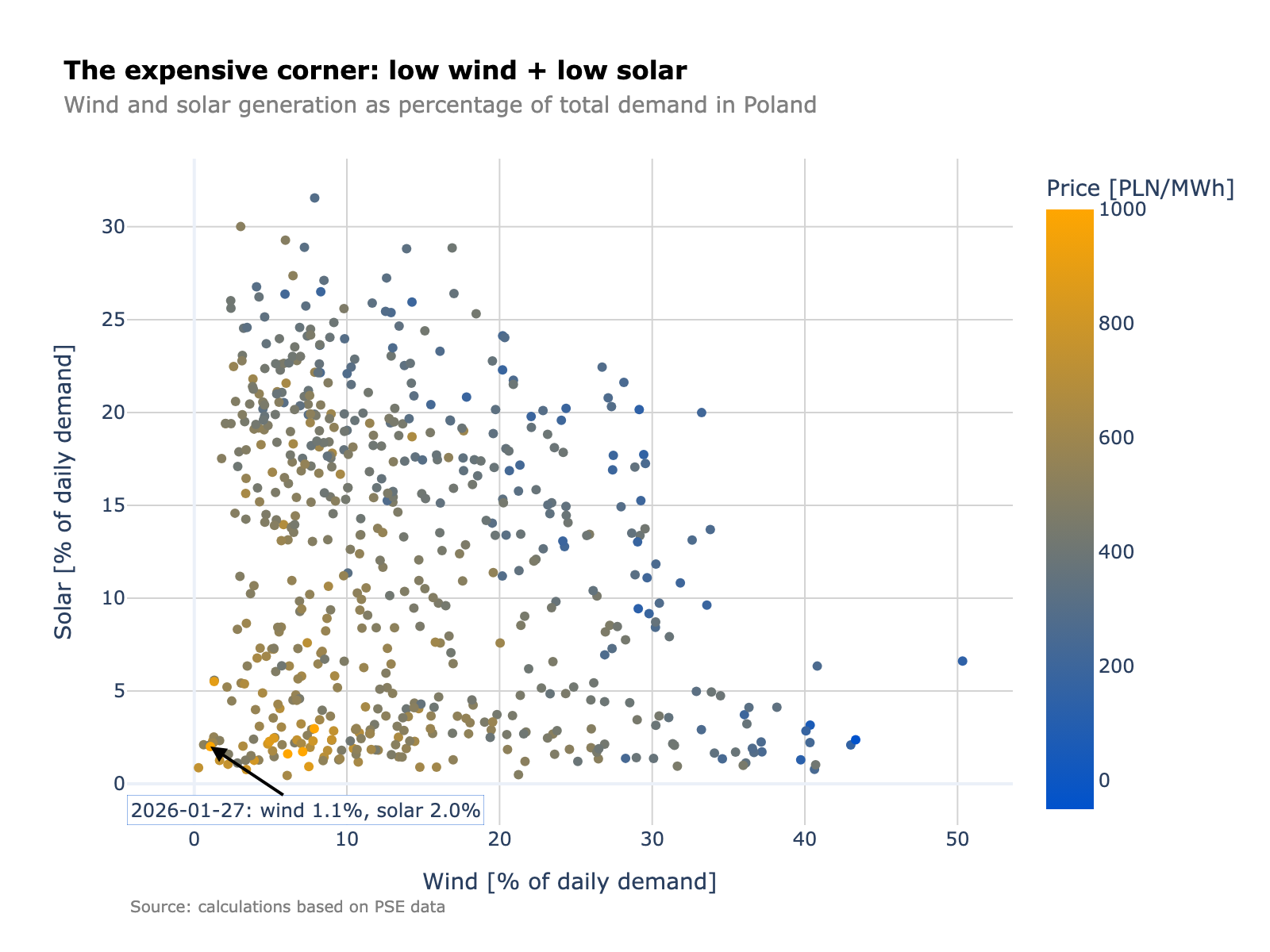
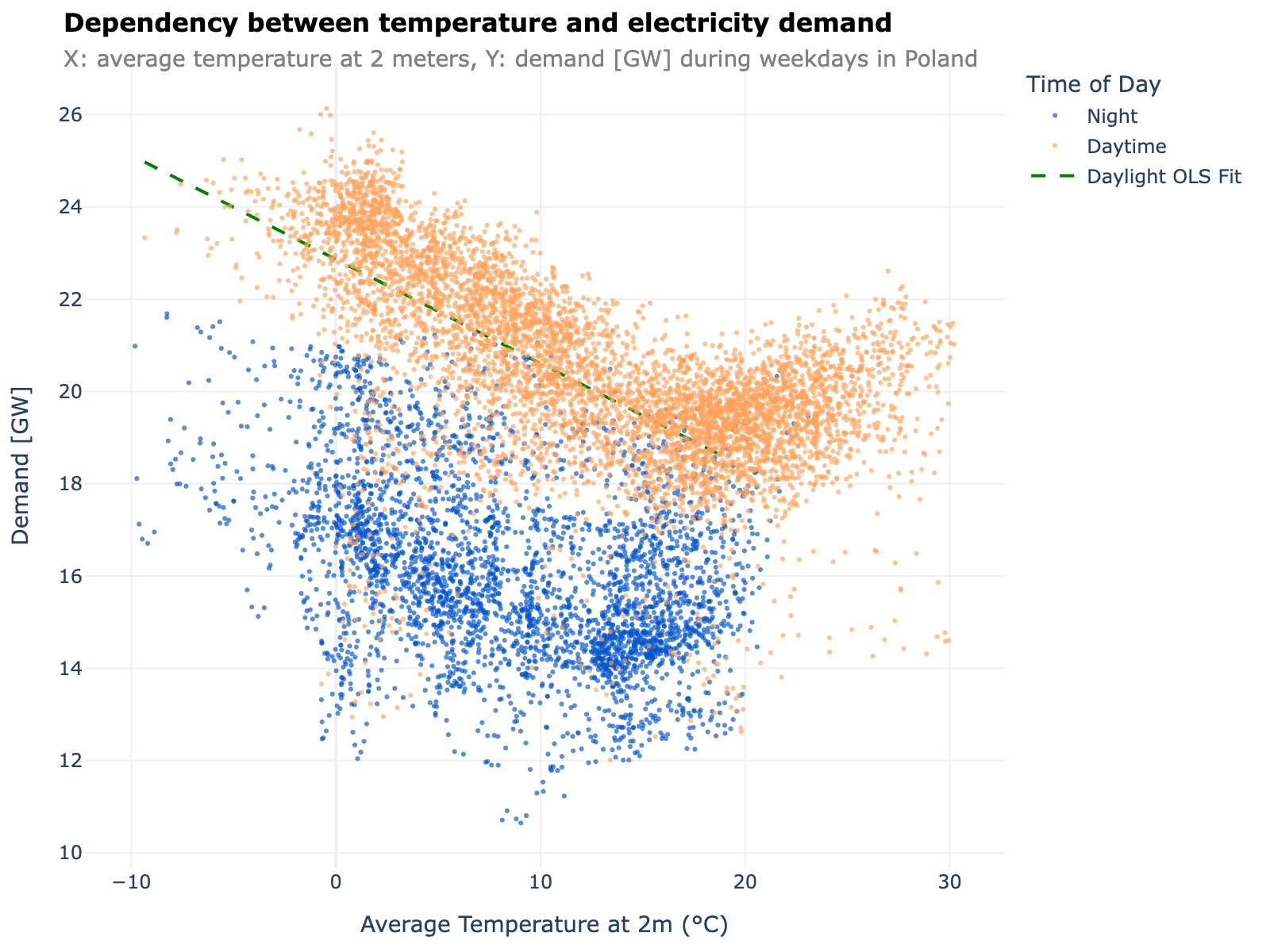
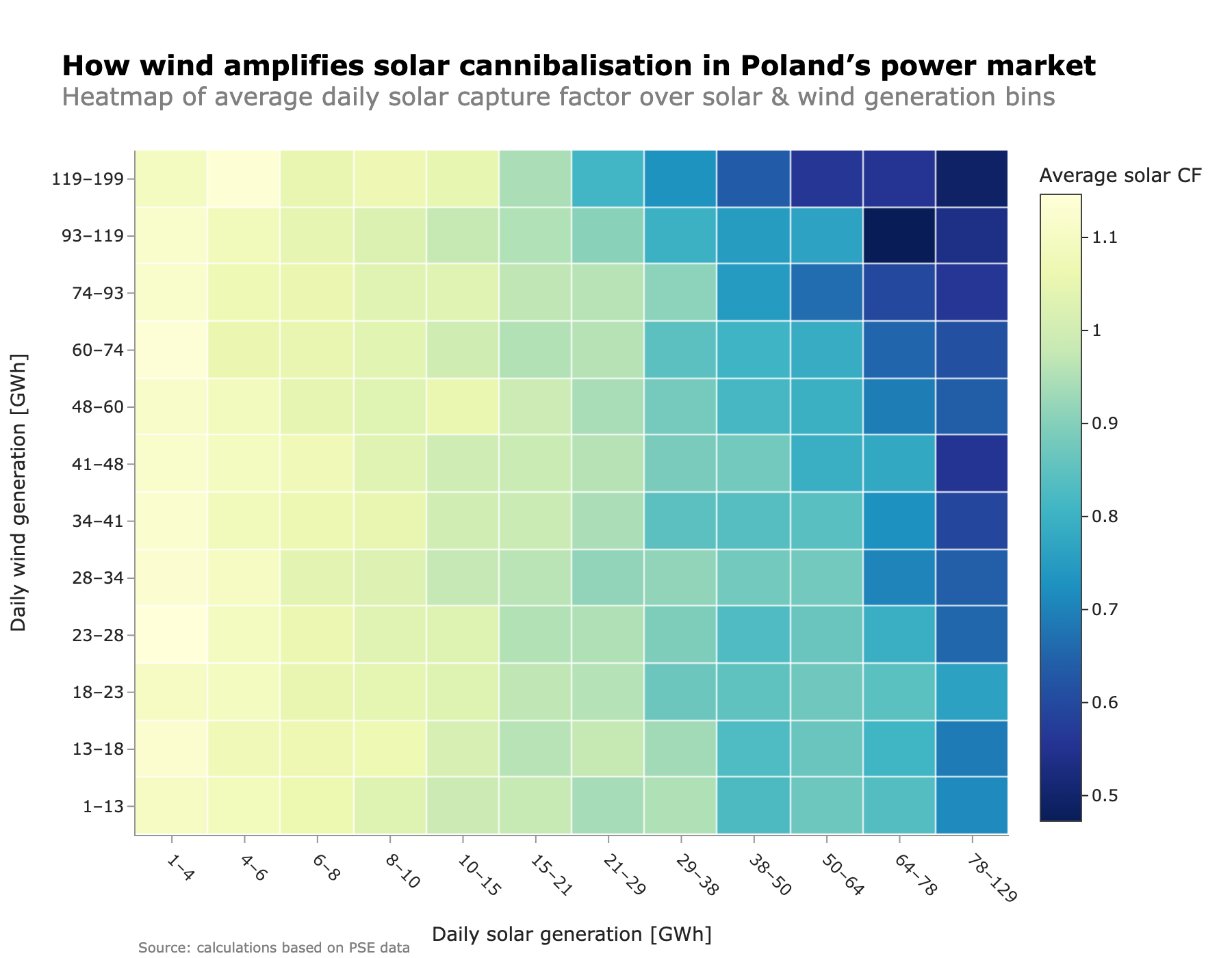
Data lakes have become the cornerstone of modern data architecture, providing a centralized repository for storing structured and unstructured data at scale. When designing a data lake, it’s crucial to consider factors such as data governance, security, and performance optimization. The future of data lakes lies in their ability to integrate seamlessly with cloud-native services and machine learning pipelines.
From Storage Dump to Strategic Platform
Early data lakes were often little more than “cheap storage”: a place to land everything and sort it out later. The result was predictable—sprawling directories, unclear ownership, and the infamous “data swamp” where no one knew what was trustworthy.
Modern data lakes are different.
They act as the backbone of analytics, machine learning, and real-time data products. They host raw events, curated datasets, and model features in one logical platform, while still enforcing governance and performance constraints.
The goal is not just to store data, but to make it discoverable, reliable, and usable across the organization.
Core Architectural Principles
A good data lake architecture is less about a specific vendor and more about a few key principles.
First, it should be cloud-native and elastic. Storage and compute scale independently, letting you ingest and keep large volumes of data without committing to fixed hardware. You attach compute engines—batch, streaming, interactive SQL—only when needed.
Second, it should support schema-on-read without sacrificing structure. Raw data can be landed quickly, but curated layers introduce well-defined schemas, contracts, and quality checks. You get the flexibility of a lake with the reliability of a warehouse.
Third, it should be multi-engine by design. The same underlying data should be usable by BI tools, data science notebooks, streaming jobs, and ML training pipelines without endless copying and reshaping.
These principles form the foundation for everything else: ingestion patterns, security models, governance processes, and performance tuning.
Organizing the Lake: Zones and Layers
Without structure, a lake turns into a junk drawer. That’s why most teams organize the lake into logical zones or layers.
A common approach is to distinguish between a raw landing zone, a cleansed or standardized zone, and a curated zone ready for consumption. The naming differs from company to company, but the intent is similar.
In the raw zone, data is ingested as close as possible to its original form. This gives you a traceable record of what actually arrived from each source and makes it easier to reprocess data if business rules change later.
In the standardized or enriched zone, you apply basic cleaning, normalization, and type standardization. Here you fix obvious data issues, align timestamps and formats, and add basic metadata that helps downstream consumers.
The curated zone is where datasets look like something the business can recognize and rely on. Subject-area models, conformed dimensions, and carefully defined metrics live here. This is the portion of the lake that BI tools, analysts, and production ML pipelines will use most heavily.
Clear boundaries between zones reduce confusion, help with access control, and make data lineage easier to trace.
Ingestion and Processing: Batch, Streaming, and Everything in Between
Modern data lakes ingest data from many sources and at many speeds.
Traditional batch ingestion—nightly exports from databases, daily files from SaaS tools—still plays an important role. It is simple, predictable, and often sufficient for reporting and planning use cases.
At the same time, more and more data arrives as streams: application events, logs, clickstreams, IoT devices, transaction feeds. These flows benefit from streaming ingestion into the lake, where events are written continuously and made available for near real-time analytics.
The most effective architectures don’t treat batch and streaming as opposing choices. They use both. Batch pipelines handle large, less time-sensitive workloads. Streaming pipelines feed real-time dashboards, anomaly detection, and latency-sensitive model features.
Processing follows a similar pattern. Distributed engines—using SQL, Spark-like frameworks, or cloud-native transformations—handle everything from simple transformations to heavy joins and aggregations. The lake becomes the shared substrate where all of this work takes place.
Governance, Security, and Discoverability
A data lake is only as valuable as it is trusted.
Governance in a lake starts with clear ownership. Every domain—Sales, Marketing, Finance, Product—should know which datasets they are responsible for, who can make changes, and how new data should be documented.
Security and privacy controls then define who can see what. Access is typically enforced at the storage layer and integrated with an identity provider. Sensitive datasets may require fine-grained permissions, encryption at rest and in transit, and audit logging for compliance requirements.
Equally important is data discoverability. Without a catalog, even well-governed data can be effectively invisible. Modern data lakes often pair storage with a metadata catalog that tracks schemas, ownership, lineage, and quality signals. Analysts and engineers can search for datasets, understand how they are built, and assess whether they are safe to use.
Taken together, these practices turn the lake from a risky “wild west” into a managed platform where data is both accessible and controlled.
Performance and Cost in a Lake World
One of the biggest shifts with data lakes is that storage is cheap and abundant, but compute is elastic and metered.
This changes how you think about performance and cost.
Instead of pre-optimizing every query, you design the system so that heavy workloads can scale out when needed and scale back down when they’re done. You partition and cluster data to reduce the amount scanned for common access patterns. You cache or materialize key aggregates where they offer clear benefits.
At the same time, you keep an eye on cost. Long-running exploratory queries, poorly designed joins, or over-provisioned clusters can inflate bills quickly. Usage monitoring, workload management, and simple guardrails help ensure that teams get value from the lake without runaway spending.
Performance and cost optimization are not one-time projects. They are part of ongoing platform operations—observed, tuned, and adjusted as workloads evolve.
Enabling Analytics and Machine Learning
A modern data lake is not just a back-office system. It is increasingly the foundation for advanced analytics and machine learning.
Analysts rely on curated tables in the lake to power dashboards and ad hoc queries. Because the lake holds both raw and modeled data, they can trace metrics back to source systems when questions arise.
Data scientists use the lake as their primary feature store. Historical events, user behavior, transaction logs, and external signals are all available in one place. They can experiment with new features, train models at scale, and save training datasets for reproducibility.
Operational teams use the same lake data to build real-time monitoring, anomaly detection, and data-driven workflows. As cloud-native ML and orchestration services mature, the boundaries between “the lake” and downstream ML pipelines continue to blur.
The more tightly your data lake integrates with analytics and ML tools, the more it becomes a strategic differentiator rather than just infrastructure.
Operating and Evolving a Data Lake
Building a data lake is not a single project; it is the start of an operational discipline.
Successful teams invest in observability: tracking pipeline health, data quality, schema changes, and usage patterns. They automate testing so that new data or transformations do not silently break downstream dashboards or models. They create simple contribution patterns so that new datasets can be added consistently rather than as one-off exceptions.
Over time, the architecture will evolve. New engines will be added, old tools will be retired, and data volumes will grow. The key is to keep the core principles intact—clear ownership, layered structure, good metadata, and strong security—while allowing technology choices to change as needed.
A Practical Path Forward
For organizations still at the beginning of their data lake journey, it’s tempting to aim for a perfect, all-encompassing platform from day one. In practice, a more incremental approach works better.
Start by identifying a handful of high-value domains and bringing their data into the lake with basic structure and ownership. Establish simple zoning, naming, and access patterns. Add cataloging and quality checks early, even if they are lightweight at first.
From there, expand the lake as new use cases demand it—more real-time feeds, more subject areas, more curated datasets for analytics and ML. Along the way, refine governance, performance tuning, and automation, turning the lake into a reliable backbone for your broader data strategy.
Done well, a data lake becomes more than a storage system. It becomes the scalable, flexible infrastructure that lets your organization adapt, experiment, and make better decisions as data volumes and demands continue to grow.